Natural Language Processing
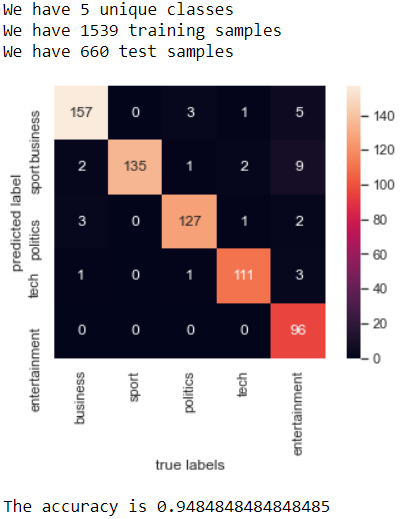
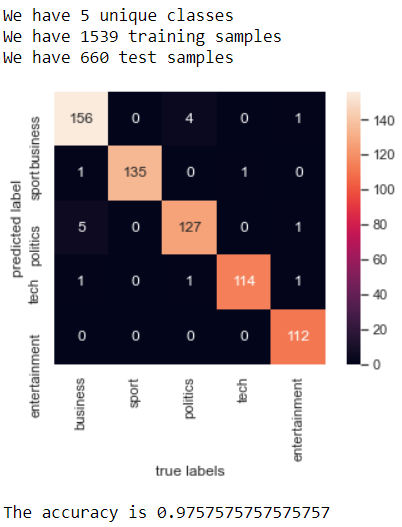
Comparing Algorithms
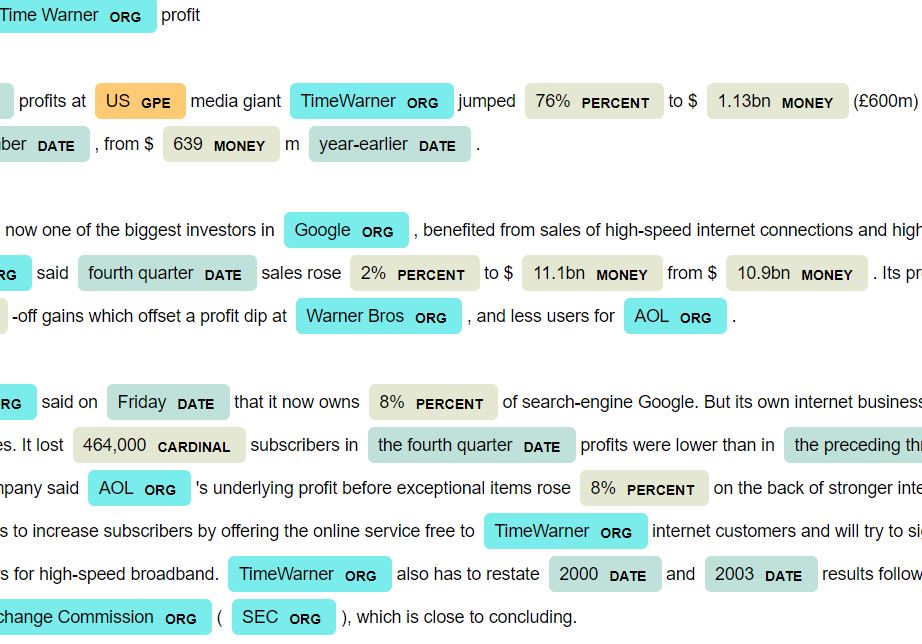
Multinomial Naive Bayes, Support Vector Machine, Latent Dirichlet Allocation, Named Entity Recognition
Download Project Briefing

Check the Code